

1.案例要求
""" 有列表:["a","a","a","b","b","c","d","d","f"], 要求去除重复的列表数据,达到效果["a","b","c","d","f"] """
2.案例分析:
(1)集合可以去重,列表转为集合,再转回列表。隐患:集合无序,索引会变。
(2)第一步:引入一个临时空列表,遍历元素列表,如果元素不在临时列表,就加到临时列表,如果临时列表已经有该元素,则不做操作。最后打印新列表即为去重后的数据。
# 方法一:利用集合去重,不推荐,因为顺序会乱
list1 = ["a","a","a","b","b","c","d","d","f"]
list1 = list(set(list1)) # 先将list1转化为set集合去重,再将集合转化为列表
print(list1)
# 方法二:定义临时空列表,遍历原始列表,保存不重复的元素,最后打印临时列表。
list2 = ["a","a","a","b","b","c","d","d","f"]
temp_list = [] # 定义一个临时空列表,用于保存临时数据。
for i in list2: # 遍历原列表,判断如果元素不在临时列表,就追加进去,如果在,就不加。
if i not in temp_list:
temp_list.append(i)
print(temp_list)
# 方法三:双重循环,外层循环遍历列表,内存循环控制删除重复元素的次数。如果元素个数统计大于1,则执行删除。
list3 = ["a","a","a","b","b","c","d","d","f"]
list3.reverse() # 先反转列表,从后往前删
for i in list3: # 外层循环控制每次需要判定的元素
for _ in range(list3.count(i)): # 内层循环控制每次执行删除元素的次数,循环多次就彻底删除。
if list3.count(i) > 1:
list3.remove(i) # 如果该元素个数大于1,则执行删除操作
list3.reverse() # 最后再反转列表,保证第一次出现的元素顺位保留下来
print(list3)3.运行结果:
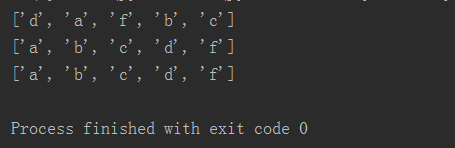
4.知识点归纳:
(1)集合去重的功能。
(2)临时列表的引入,可以解决很多实际的问题。
(3)如果有要求,要考虑变换过后,原列表内存地址会不会发生改变,考虑会不会占用多余内存空间。例如:方法一,顺序乱了,而且内存地址改变了。方法二,顺序没乱,但多申请了临时变量的内存地址。方法三,顺序没乱,内存地址也没变。








