
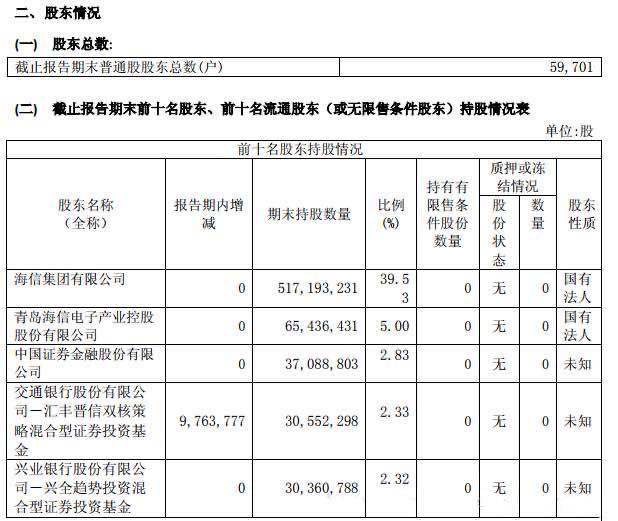
PDF文件表格样例
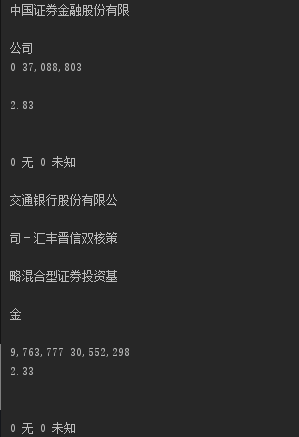
Python解析结果

其他样式解析,如Tika
1、TEXT格式
Tika tika = new Tika();
tika.setMaxStringLength(100 * 1024 * 1024);
try (InputStream stream = new FileInputStream(new File("600060_2018_zB.pdf"))) {
return tika.parseToString(stream);
}
Text格式解析结果
2、XHTML格式
ContentHandler handler = new ToXMLContentHandler();
AutoDetectParser parser = new AutoDetectParser();
Metadata metadata = new Metadata();
try (InputStream stream = new FileInputStream(new File("600060_2018_zB.pdf"))) {
parser.parse(stream, handler, metadata);
return handler.toString();
}
XHTML格式解析结果

解析PDF常用组件(PdfBox、iText、Tika等)都无法将表格数据解析成有规则的格式。解析后格式基本是TEXT、XHTML等导致处理表格数据变的非常复杂。
根据对比我们可以发现,用Python解析PDF的表格数据更为简单方便,下期我们就为大家带来Python解析PDF具体的方法。更多Python学习推荐:PyThon学习网教学中心。





