

1、simHash简介
simHash算法是GoogleMoses Charikear于2007年发布的一篇论文《Detecting Near-duplicates for web crawling》中提出的, 专门用来解决亿万级别的网页去重任务。
simHash是局部敏感哈希(locality sensitve hash)的一种,其主要思想是降维,将高维的特征向量映射成低维的特征向量,再通过比较两个特征向量的汉明距离(Hamming Distance) 来确定文章之间的相似性。
什么是局部敏感呢?假设A,B具有一定的相似性,在hash之后,仍能保持这种相似性,就称之为局部敏感hash
汉明距离:
Hamming Distance,又称汉明距离,在信息论中,等长的两个字符串之间的汉明距离就是两个字符串对应位置的不同字符的个数。即将一个字符串变换成另外一个字符串所需要替换的字符个数,可使用异或操作。
例如: 1011与1001之间的汉明距离是1。
相关推荐:《Python基础教程》
2、simHash具体流程
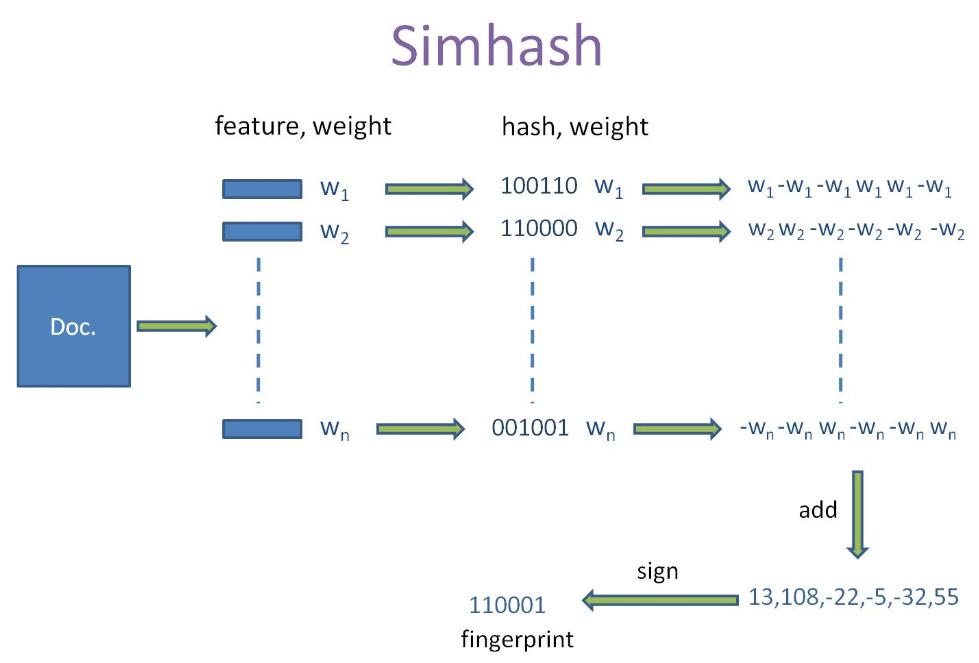
simHash算法总共分为5个流程: 分词、has、加权、合并、降维。
分词
对待处理文档进行中文分词,得到有效的特征及其权重。可以使用TF-IDF方法获取一篇文章权重最高的前topK个词(feature)和权重(weight)。即可使用jieba.analyse.extract_tags()来实现
hash
对获取的词(feature),进行普通的哈希操作,计算hash值,这样就得到一个长度为n位的二进制,得到(hash:weight)的集合。
加权
在获取的hash值的基础上,根据对应的weight值进行加权,即W=hash*weight。即hash为1则和weight正相乘,为0则和weight负相乘。例如一个词经过hash后得到(010111:5)经过步骤(3)之后可以得到列表[-5,5,-5,5,5,5]。
合并
将上述得到的各个向量的加权结果进行求和,变成只有一个序列串。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]进行列向累加得到[-7,1,-9,9,3,9],这样,我们对一个文档得到,一个长度为64的列表。
降维
对于得到的n-bit签名的累加结果的每个值进行判断,大于0则置为1, 否则置为0,从而得到该语句的simhash值。例如,[-7,1,-9,9,3,9]得到 010111,这样,我们就得到一个文档的 simhash值。
最后根据不同语句的simhash值的汉明距离来判断相似度。
根据经验值,对64位的 SimHash值,海明距离在3以内的可认为相似度比较高。
3、Python实现simHash
使用Python实现simHash算法,具体如下:
# -*- coding:utf-8 -*-
import jieba
import jieba.analyse
import numpy as np
class SimHash(object):
def simHash(self, content):
seg = jieba.cut(content)
# jieba.analyse.set_stop_words('stopword.txt')
# jieba基于TF-IDF提取关键词
keyWords = jieba.analyse.extract_tags("|".join(seg), topK=10, withWeight=True)
keyList = []
for feature, weight in keyWords:
print('weight: {}'.format(weight))
# weight = math.ceil(weight)
weight = int(weight)
binstr = self.string_hash(feature)
temp=[]
for c in binstr:
if (c == '1'):
temp.append(weight)
else:
temp.append(-weight)
keyList.append(temp)
listSum = np.sum(np.array(keyList), axis = 0)
if (keyList == []):
return '00'
simhash = ''
for i in listSum:
if (i>0):
simhash = simhash + '1'
else:
simhash = simhash + '0'
return simhash
def string_hash(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2**128 - 1
for c in source:
x = ((x*m)^ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
# print('strint_hash: %s, %s'%(source, x))
return str(x)
def getDistance(self, hashstr1, hashstr2):
'''
计算两个simhash的汉明距离
'''
length = 0
for index, char in enumerate(hashstr1):
if char == hashstr2[index]:
continue
else:
length += 1
return length
if __name__ == '__main__':
simhash = SimHash()
s1 = simhash.simHash('我想洗照片')
s2 = simhash.simHash('可以洗一张照片吗')
dis = simhash.getDistance(s1, s2)
print('dis: {}'.format(dis))对于短小的文本,计算相似度并不十分准确,更适用于较长的文本。









