

Excel是大家工作当中使用频率比较高的一款办公软件了所以我们很有必要学习一下,那么Python是如何处理excel呢,下面就来讲讲~~
更多Python操作Excel文件的相关知识,可以参考这篇文章:《Python自动化办公之操作Excel文件》
1.两大库xlrd,xlwt
1).Python操作excel主要用到xlrd和xlwt这两个库
即xlrd是读excel,xlwt是写excel的库,名字也蛮好记得,xl是excel的缩写,rd是read,wt是write.xlrd可以解析微软的.xls and .xlsx两种各种的电子表格
2).如何安装
用pip install xlrd就可以安装xlrd模块
用pip install xlwt就可以安装xlwt模块
如果小伙伴是用Pycharm的话更简单,直接打开File/Setting/Project/Project Interpreter,然后选择左边的绿色加号安装
2.如何读一个excel文件
比如有这样一个"user_data.xlsx"表格,第一个sheet叫"data",内容如下:
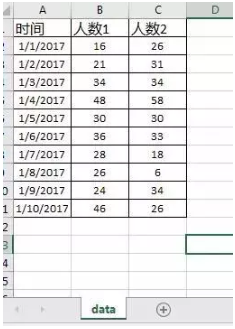
1).打开表格
file_name='user_data.xlsx' excel_file=os.getcwd()+'\'+file_name rdata=xlrd.open_workbook(excel_file) print type(rdata) >>>
2).获取表格的基本信息
print 'sheets nums:',rdata.nsheets#excel sheets 个数 >> sheets nums: 1
3).每个sheets名字
print 'sheets names:',rdata.sheet_names()#excel sheets 每个名字 >> sheets names: [u'data']
4).每个sheet的行列总数,比如第一个sheet
sheet1=rdata.sheet_by_index(0) print 'rows:',sheet1.nrows print 'clos',sheet1.ncols >>rows=11,cols=3
5),获取行,列的对象
获取第一行的内容
sh1=rdata.sheet_by_index(0) print sh1.row(0) >> [text:u'\u65f6\u95f4', text:u'\u4eba\u6570'] print sh1.row_values(1) >> [u'\u65f6\u95f4', u'\u4eba\u6570'] #返回的是列表对象,中文会转成的unicode显示
获取第二列的内容
print sh1.col(1) >> [text:u'\u4eba\u6570', number:16.0, number:21.0, number:34.0, number:48.0, number:30.0, number:36.0, number:28.0, number:26.0, number:24.0, number:46.0] #返回的是列表对象,text表示是文本对象,number是数字 >>print sh1.col_values(1) [u'\u4eba\u6570', 16.0, 21.0, 34.0, 48.0, 30.0, 36.0, 28.0, 26.0, 24.0, 46.0] 我们可以利用列表切片访问:第二列到第5列 >>print sh1.col_values(1)[1:5] [16.0, 21.0, 34.0, 48.0] 也可以利用默认的col_values参数 col_values(self, colx, start_rowx=0, end_rowx=None) print sh1.col_values(1,1,5) >> [16.0, 21.0, 34.0, 48.0]
更多学习内容,请点击python学习网。
python处理excel相关学习,推荐访问:









